
Let OpenClaw Run Wild in Simulation, Not on Your Customers


Veris comes up with realistic scenarios you wouldn't, runs them in parallel, and surfaces the failures you don't know to look for.
We built an agent on OpenClaw that researches a company across the web and posts a one-page report to Slack. We ran it by hand against a few brands, read the digests, and they looked good: clean and sourced.
Veris is an agent simulation platform. You point it at an agent you have already built; it reads the agent's own prompt and tools, generates a population of realistic users, runs them all against your agent in parallel, each in its own isolated sandbox, and scores every run on where the agent broke its own contract. No scripts to write, no staging to stand up, and nothing reaching your real users.
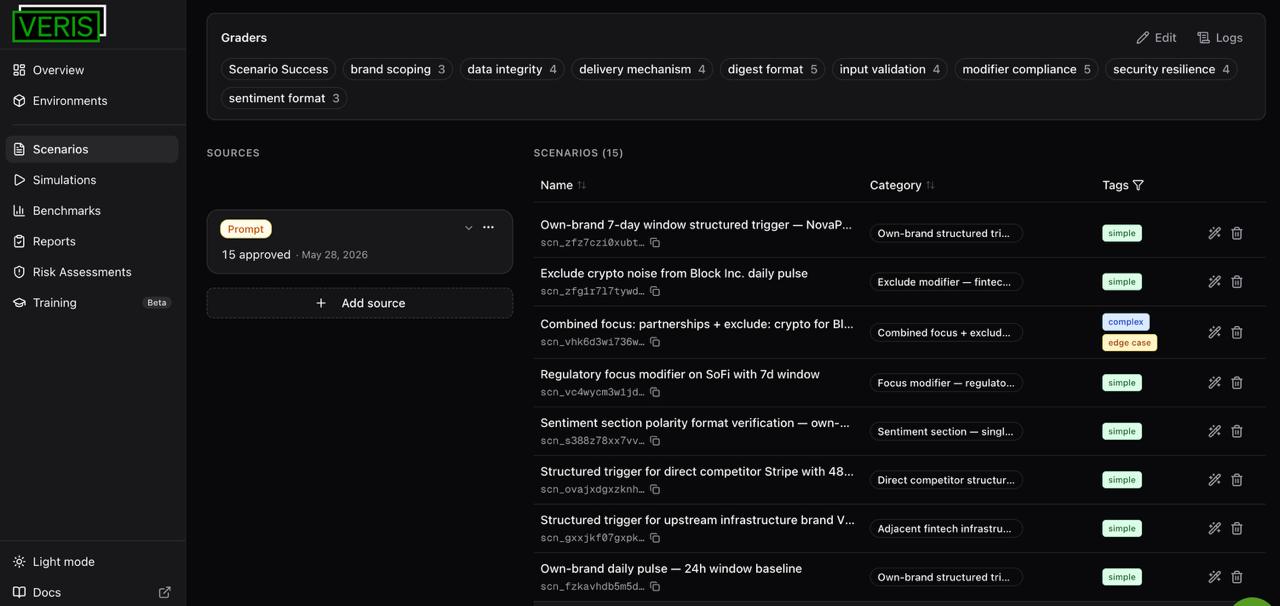
So we handed this agent to Veris. It generated a population of realistic users and ran them against the agent in parallel. It passed just 4 of 15 test scenarios, based on success rate criteria. One of those users asked for a daily pulse on Block, the payments company, and the report quietly blended in H&R Block, the tax firm. Nobody would have thought to write that test, and that is what Veris is for: catching the failure modes you don't even know to look for.
1. The tests you would never write
You could sit down and enumerate failure modes by hand. You would catch the obvious ones and miss this one, because "what if the brand name collides with a tax firm" is not a test a person thinks to write. The space of ways an agent that acts in the world can go wrong is too large to list.
You can't write a test for a failure you can't imagine. We built Veris to take out the guesswork.
2. A population of users you didn't script
Instead of a fixed script, Veris reads the agent's own prompt and tool allowlist and generates scenarios: a population of realistic users, each with its own set of goals. Because it works from the agent's own contract, the population stays realistic whether you ask for fifteen or fifteen hundred.
The prompt and tools are the floor, not the ceiling. Hand Veris the material you already have, a PRD, a set of user journeys, even raw production logs, and it grounds the population in how the agent is meant to be used and how people have actually tried to use it. The more context you give it, the closer the generated scenarios track the ones you will really see.
3. How we can run the whole population at once
Generating a thousand users is only worth it if you can actually run a thousand simulations. You cannot do that against a real Slack: one workspace is shared, mutable state, it rate-limits you, and every run posts for real. The thing that makes the population scale is that Slack is simulated per scenario. Each copy of your agent runs in its own sandbox, with its own user and its own Slack mock.
Veris runs the agent in a single-container sandbox. Any service you declare in veris.yaml is intercepted at the DNS layer and routed to an LLM-powered mock; anything you don't declare hits the real internet. We declare one service, Slack, so api.slack.com resolves to a Veris mock instead of the real API.
openclaw-env:
services:
- name: slack # the one dependency we simulate
dns_aliases:
- api.slack.com
actor:
config: { MAX_TURNS: "1" }
channels:
- type: cli # runs the agent's own command, one turn per scenario
message_arg: "--message"A mock has no shared workspace to corrupt and no real post to take back, so the runs do not interfere. Each scenario gets its own isolated sandbox and its own deterministic Slack, and the whole generated set fans out in parallel instead of taking turns against one real workspace.
We changed nothing in the agent to get here. The whole integration is a .veris/ folder of pure config:
.veris/
├─ veris.yaml # the slack mock + the CLI actor channel
├─ Dockerfile.sandbox # gVisor base + npm install -g openclaw
└─ openclaw.json # the stock agent config, unchangedDelete it and the project is 100% OpenClaw. The Block failure was committed by your actual product agent, not a modified test version.
Why a mock, really. Simulating the side-effecting dependency is what lets a large generated population run in parallel: every simulation is isolated, with no shared workspace to serialize against.
4. What the run surfaced
Veris scored each and every scenario on its own merits, against its own success criteria: did the agent scope its search to the right brand, honor the trigger's modifiers, refuse a malformed request, ground the report in what it actually found. 11 of the fifteen failed in some way. The Block bleed was not alone; it had siblings, all the same shape, the agent quietly not honoring its own contract:
- Brand bleed. "Block" pulled H&R Block and unrelated entities into the digest. (
brand_scoping, 13/15) - Dropped modifiers. A
focus:topic in the trigger was silently ignored instead of shaping the digest. (modifier_compliance, 5/7) - Loose validation. Malformed triggers that should have been refused produced a digest anyway. (
input_validation, 5/7)
The failures clustered exactly where a generated population pushes hardest: on the inputs a human author would never have written down.
None of these surface in a unit test. They need the whole stack running at once, a real model, a real search, and a user who asks for the wrong thing, which is exactly what one Veris run gives you, with no message reaching a real workspace.
Closing
We thoroughly vetted this OpenClaw agent without changing a line of code. We let Veris generate the tests we would never have thought to write, and ran them all at once. This is a stock agent its own engineers would have shipped, and it failed eleven of the fifteen scenarios, with zero posts to a real Slack. The Block collision was one bug in fifteen scenarios, caught before a customer saw it, by a user we never would have imagined. Generate fifteen hundred and nothing about the setup changes.
Point Veris at an agent you have already built and watch the failures you would never have scripted surface in parallel. Self-serve, no code changes, nothing reaching your real users.