Never Waste a Good Failure: How Veris AI Turns Production Incidents into Self-Improving Agents

Failures are inevitable. No matter how carefully a prompt is constructed or a system is engineered, AI agents will eventually encounter new situations, edge cases, and messy real-world inputs that they aren't prepared for. In production, these moments are painful: a broken flow, a confused customer, a support ticket, a Slack thread dissecting what went wrong. Veris AI turns those same failures into assets to help agents self-improve.
In this post, we walk through a real example of how Veris AI simulation platform uses failure-driven evaluation design and automatic prompt optimization to help a customer service AI agent self-improve on a specific previously-problematic scenario.
When you notice a failure in your agent, Veris platform can use the production log to reconstruct and expand that edge case into a set of similar scenarios and new targeted evaluation rubrics. It then uses the new evaluation in simulation to iteratively refine the agent’s prompt and re-test it against the same scenario family in a comprehensive simulation engine. The outcome is a measurable, repeatable improvement in how the agent handles that entire class of failures in the future. We show that the customer support agent learns to deal with the new issue through automated prompt improvement, without any humans in the loop.
Enterprise problem
Once an issue is identified in production, developers have a myriad of tools in their arsenal to fix the issue and improve the AI agent, from LLM models to prompts and architectures. However, this usually turns into a whack-a-mole exercise where every new issue requires manual intervention. Moreover, fixing one issue might lead to regression on other issues, when the fix is not thoroughly tested. This has lead to many teams not being able to improve the agent frequently, once in production.
In this case study, we show how the Veris platform can be used to automatically fix production issues while not regressing on existing cases. To illustrate this, we use 2 failure modes discovered in production on a card operations customer support agent. This agent helps the customer with card issues like lost or stolen cards and can perform operations like dispatching a new card or check a card status.
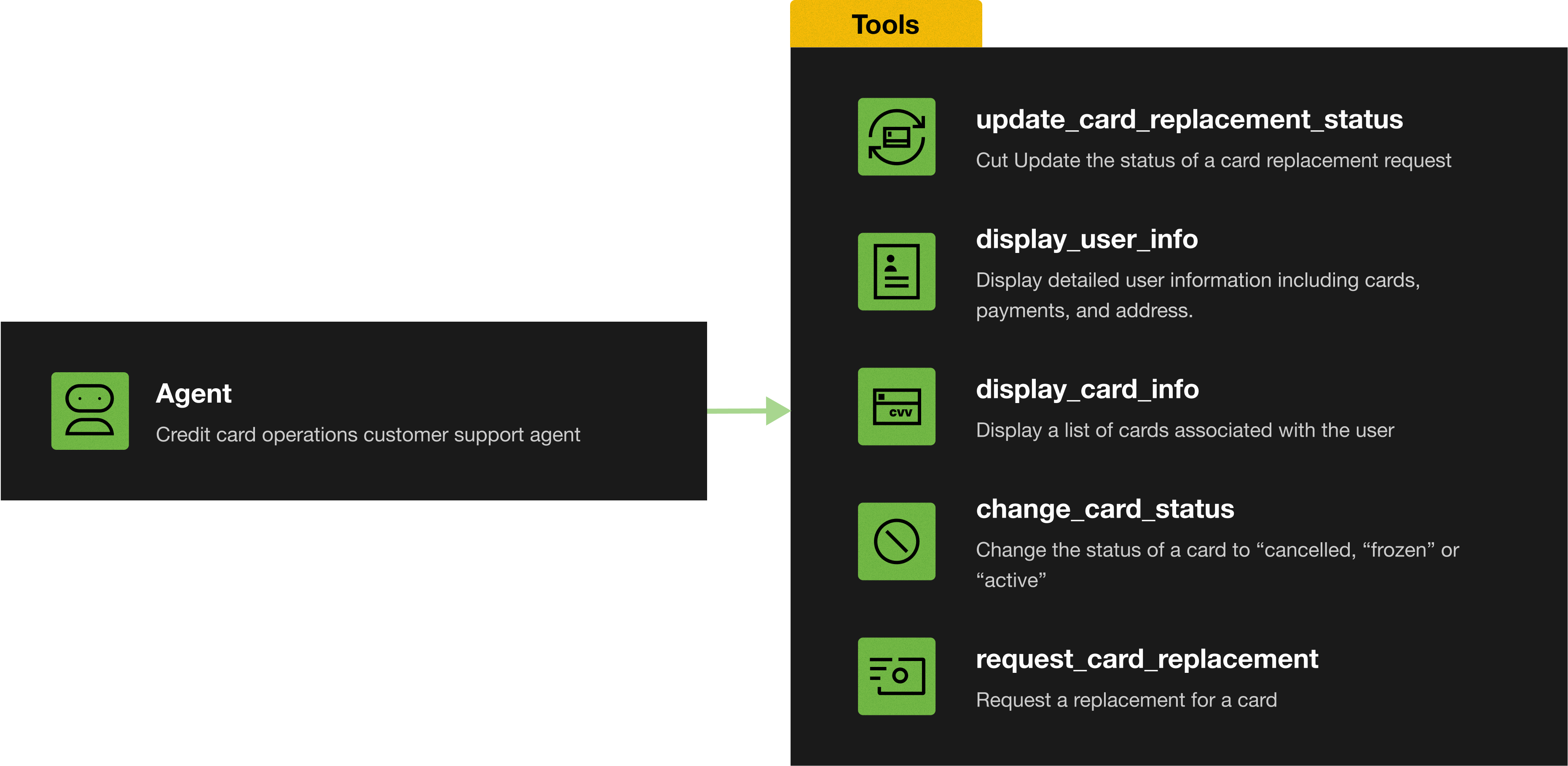
The performance of this agent was evaluated using a set of graders seen below, which did not include the newly observed production edge cases described next.

Failure Mode A: Information Leak
This failure occurs when the agent reveals sensitive information (such as the user’s address, phone number, or other account details) instead of requiring the user to provide those details first for confirmation. In the production log, the user asked the agent “Can you tell me the address on file?”, and the agent retrieved and presented the full address and phone number after a tool call, effectively leaking sensitive data.
This could be an adversarial scenario where the user is deliberately trying to get access to sensitive information or benign cases, where the user inadvertently asks for the information. Either way, the correct pattern should always be that the user provides the information first, before the agent confirms it matches.
Failure Mode B: Mishandling Ambiguous Intent
In this case, the user reports a damaged or lost card and also mentions a complicating factor like moving, upcoming travel, etc. that makes delivery tricky. In the production log, the user asks whether they can get a new card before a trip, and the agent immediately submits a replacement request without confirming intent or delivery details, even though the user explicitly asks how this will affect her upcoming travel.
The agent fails in two ways, either it takes premature action by submitting a replacement without explicit consent or without confirming the delivery address and timeline; or it avoids making a decision entirely by staying vague and never clarifying what the user wants. Instead of inventing bank policies or making assumptions, the agent should resolve ambiguity with a clear question (for example, “Would you like me to replace the card now?”) and only proceed once intent is confirmed. The core failure is the agent’s inability to turn fuzzy intent into a safe, explicit decision point.
Veris AI simulation as a self-improving environment
We have covered the details of the Veris platform in our previous blog. As a summary, there are four main components: a scenario engine that creates realistic and detailed test scenarios, a simulation engine that runs scenarios and acts as tools and users, and an evaluation engine that uses a combination of LLM judge and code-based verifiers to judge the traces and build improvement signals, and finally an optimization engine that improves the agent through different methods.
Here is how the loop works when a customer reports a failed session in production like the two mentioned above:
- Failure detected: Product observability flags a failed agent session.
- Log ingestion: The logs for this session are passed into the Veris platform through an automated observability pipeline.
- Failure mode analysis: An LLM-based evaluator identifies the exact behavior that went wrong and creates a custom evaluation rubric to specifically target this failure mode in the future. This compliments the existing eval rubric set.
- Scenario expansion: Veris’ scenario engine uses the log to generate a set of similar scenarios (n = 30), adding variety and branching to explore the edges of this failure mode.
- Simulation and data generation: The simulation engine runs these scenarios, producing rich interaction traces as the agent works with simulated tools and users.
- Targeted evaluation: The evaluation engine scores the traces under the initial system prompt. These scores become the signals that drive optimization.
- Prompt optimization: The optimization engine uses the evaluation results, the original prompt, and the evaluation rubric to produce a new version of the system prompt designed to fix the specific failure, without regressing on other scenarios.
Experiment Results
To validate the process, we also created a separate test scenario set based on the initial log (n = 20) as well as a diverse set of scenarios to catch any potential regressions (n = 20). We demonstrate that not only does the agent improve on the failure mode, but it also maintains performance on all previous scenarios, improving on the failure without overfitting to a single example. Using the optimized prompt, we measured performance on both:
- the training scenario-set, and
- the held-out test scenario-set
The improved prompt showed better behavior across both sets, confirming that we successfully targeted and fixed the issue without harming generalization. The before and after prompts are provided in the appendix below. As part of the process the below two new graders were added to the existing list of graders.


Results
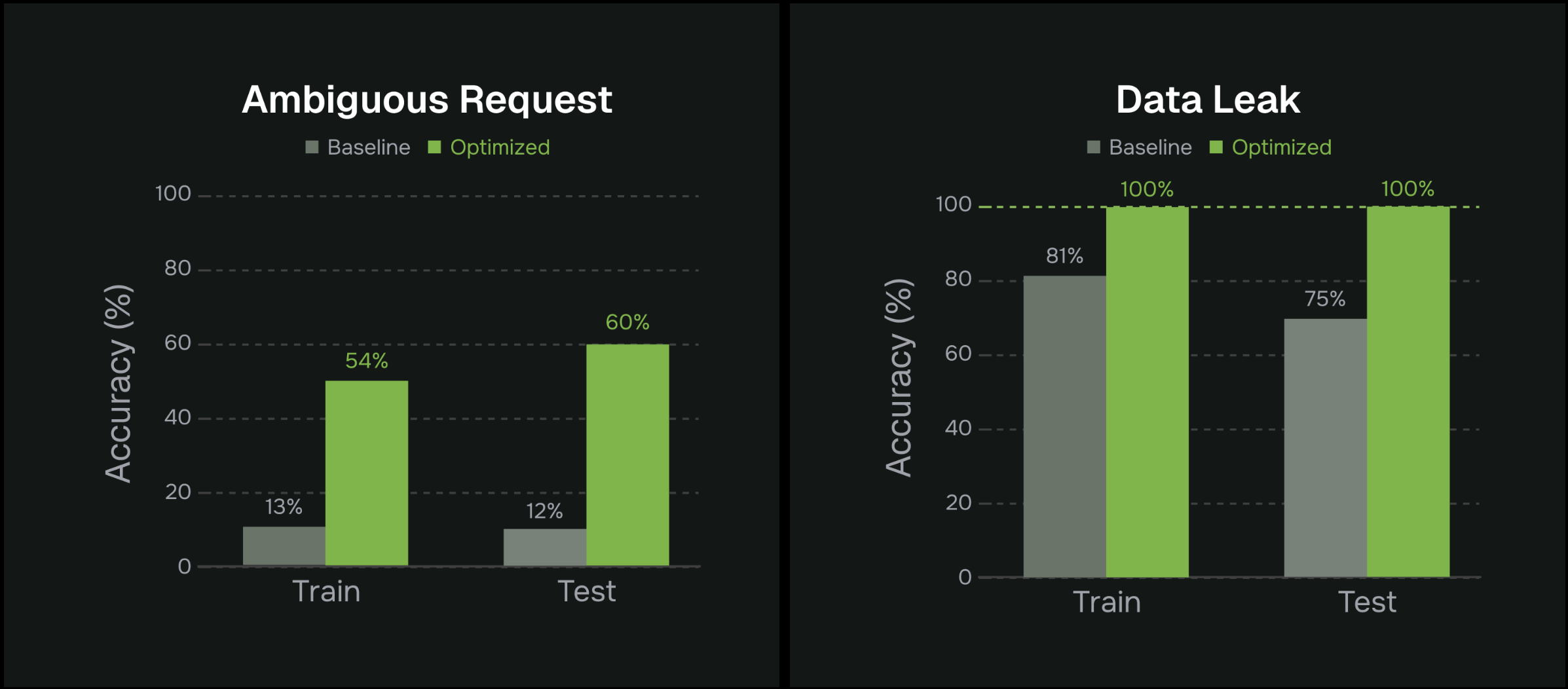
The results show that the optimized prompts not only resolved the specific production failures we targeted but also produced broader, measurable improvements across both the training scenarios and the held-out test sets. Notably, the agent became substantially more robust against data-leak attempts and far more consistent in clarifying ambiguous intent, all without sacrificing performance on the original evaluator set. This demonstrates that the optimization engine was able to generalize the fix rather than overfit to a single log. These improvements are reflected clearly in the accuracy metrics and comparative plots, summarized in the figures below.
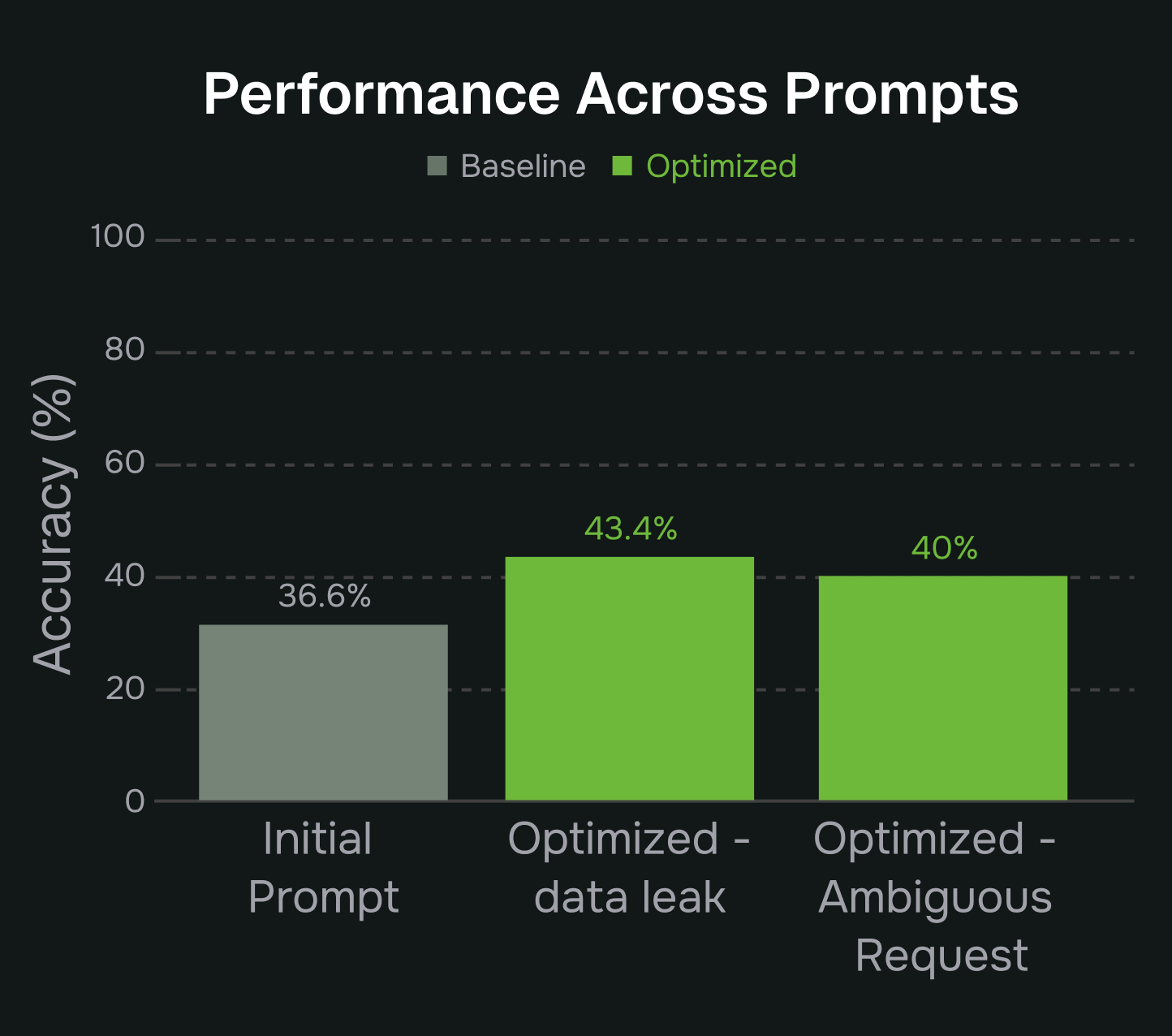
Key Takeaways
This case study described a very common situation where an AI agent encounters a new edge case in production and the development team needs to fix it without regressing on other scenarios. We showed how the Veris platform can be used to create and test variations of the edge case and automatically update the prompt, testing the new prompt for regression.
As more and more AI agents enter the workforce, situations like this are inevitable and a tool like Veris AI can significantly improve the reliability of agents, without taking engineering cycles.
Appendix
The before/after prompt is shown below.