
Environments, Not Examples: How Reinforcement Fine-Tuning Trains Enterprise-Grade Domain-specific Agents

Introduction
Enterprises need domain-specific agents that can reliably operate within their own data, tools, and workflows. Agents built with large commercial models lack the specificity and run-time performance for most enterprise agentic applications. Post-training is a powerful tool to achieve this, and realize benefits in performance, cost, and latency. Furthermore, continuous post-training is the best way to take advantage of valuable enterprise data to improve model performance and deepen the long-term defensibility.
In this case study, we highlight a Detection Engineering Cybersecurity AI agent which was reinforcement fine-tuned (RFT) using Veris AI’s simulation environment. This AI agent generates high-quality Sigma rules based on user requests. The result is a domain-specific AI agent operating on a relatively small local model that performs on par with major commercial models but at a fraction of the cost and latency.
The enterprise problem
Post-training is the missing “last mile” in developing enterprise agents. Instead of hoping a general-purpose agent can understand enterprise schemas, policies, and tools, companies explicitly shape agent behavior around their data and domain. RFT can take that idea further using the Veris Simulation Environment. Rather than training on static data and labels, companies can train against an environment that can judge outcomes and give feedback based on how the agent actually behaves.
We used RFT to post-train a Sigma rule generation agent. Sigma rules are standardized detection rules for security logs. They are open, YAML-based detection signatures for log data that give defenders a vendor-agnostic way to describe and share threat detection logic across different SIEM and log platforms.
Thread-hunting Detections AI agent
Sigma is an open-source and extensible framework for generating detections as code for organizations. This flexibility allows teams to find threat vectors that traditional security vendors might miss.
The ability to create custom detective controls means that organizations can have a vendor-agnostic, business-centric detection stack.
Generating Sigma rules is a hard problem for an AI agent. Field names must match real log schemas and Windows event IDs, YAML must parse correctly, and the logic must reflect the actual behavior being detected. A rule that “looks plausible” but references fake fields or invalid events is useless. One of the biggest pitfalls in Sigma authoring is that poorly written or poorly evaluated rules generate noise instead of signal. This makes Sigma rule generation a strong benchmark for enterprise agents: success isn’t about sounding smart, it’s about producing precise, executable detection logic.
Validating a generated rule is also challenging, as there are many ways of describing the same rule. Both human experts and LLMs-as-a-judge can struggle with validating Sigma rules. This is one of the greatest pitfalls of Sigma rule creation: when poorly written or evaluated, it is immensely noisy.

How can RFT solve this problem?
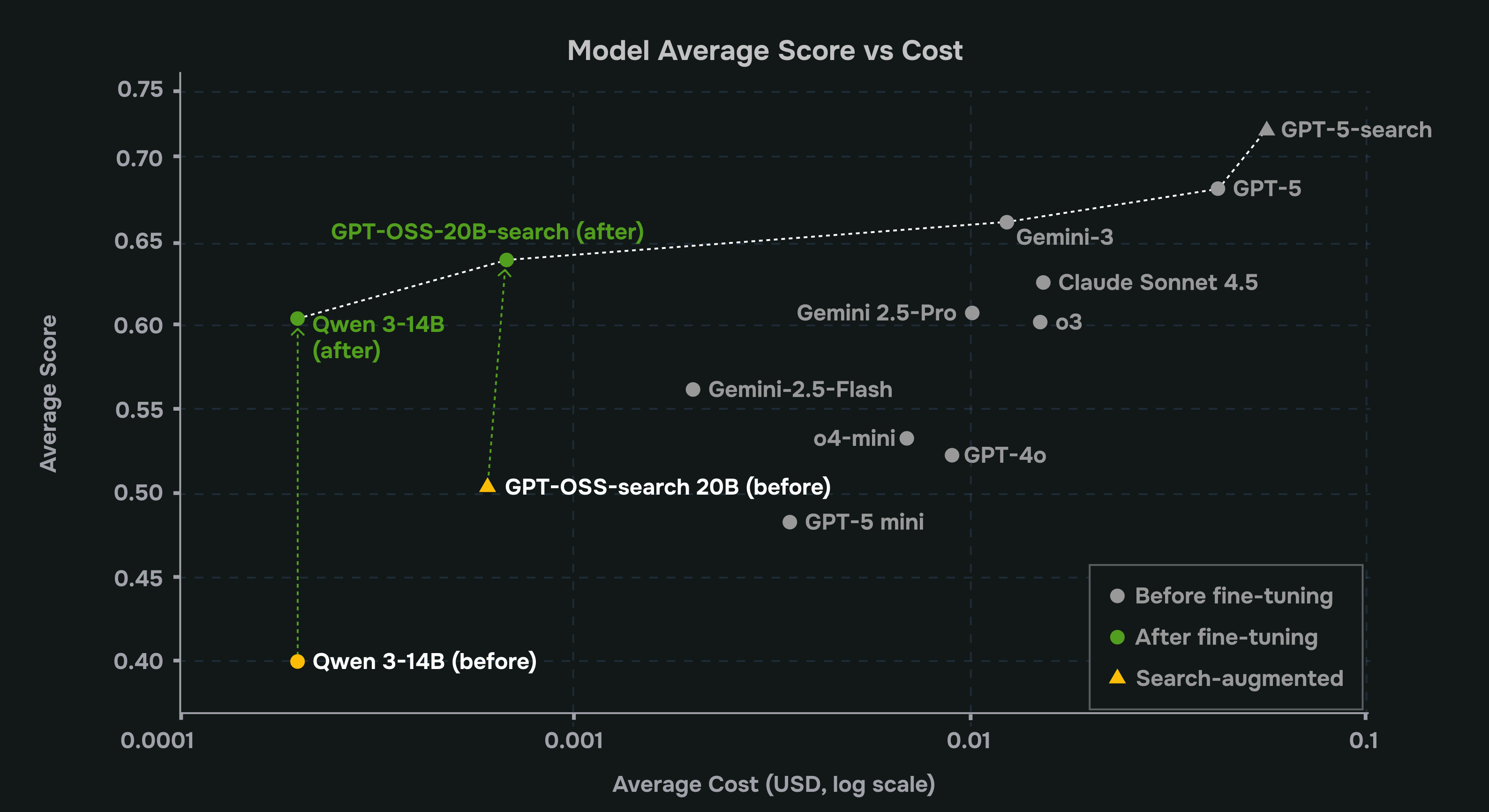
Our starting point was an agent powered by a small LLM (Qwen3-14B and GPT-OSS-20B) tasked with generating Sigma rules from natural-language descriptions of detection goals or incident narratives. Out of the box, it struggled: hallucinated fields, invalid syntax, and semantically weak rules. A large commercial LLM did better, but at a significantly higher marginal cost per generated rule.
The question became: can we teach the small model to behave like a specialized Sigma rule generator through RFT?
Instead of collecting more labeled examples, which is expensive and requires expert human time, we built a simulated environment around the Sigma generation task. This environment acted as a “training ground” for the agent. In the simulation, simulated user personas generate the kinds of detection requests analysts really make. The agent responds with a Sigma rule, which as described above, is not easy to validate. Instead, we evaluate the rule in the environment against simulated logs.
The details of the technical implementation can be found in this technical report.
Does it actually work?
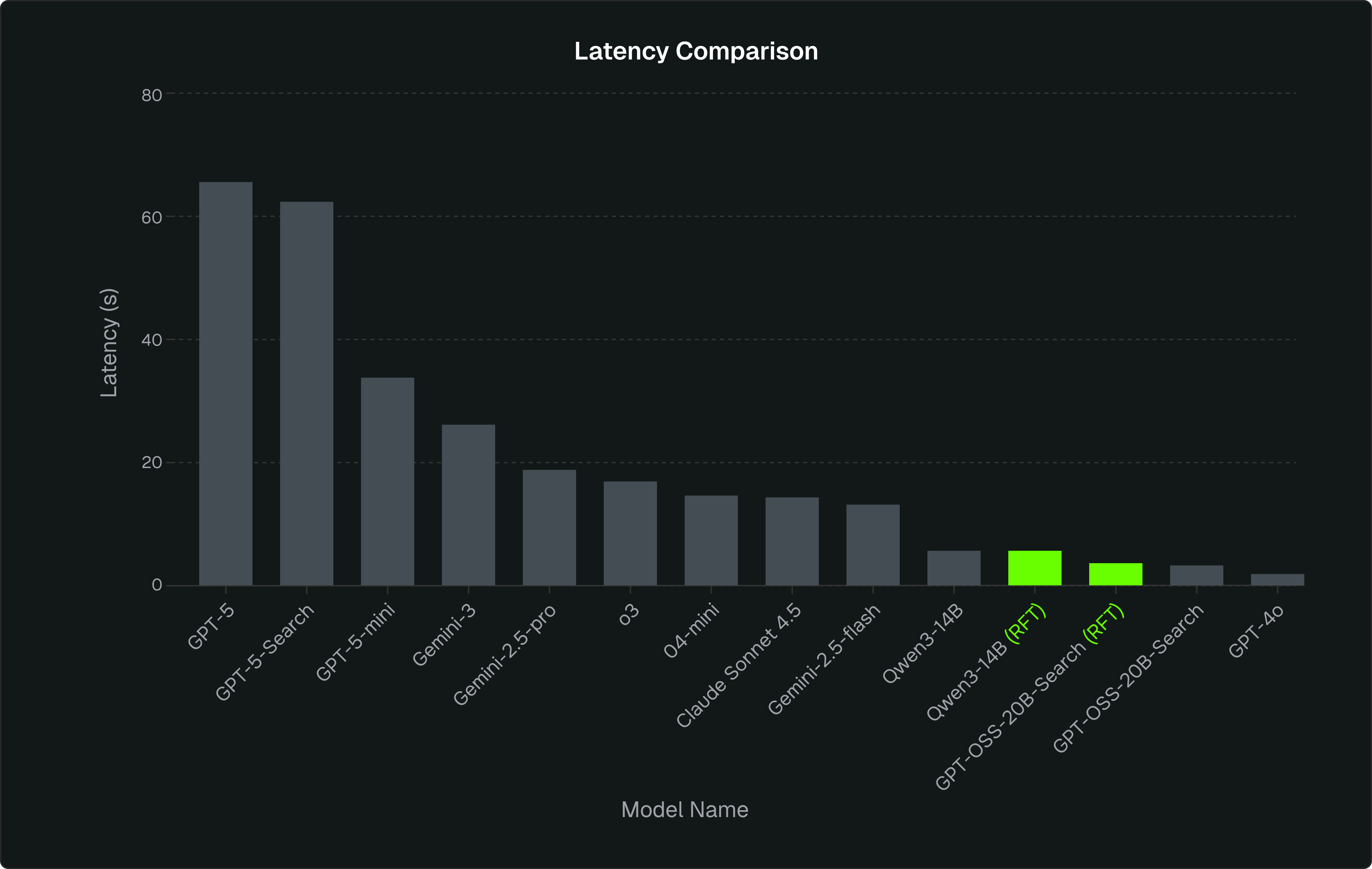
With only ~100 training rules and a simple reward function, RFT moved the needle a lot. Both models (Qwen3-14B and GPT-OSS-20B-search) jumped from “mostly right but fragile” to “consistently correct and grounded,” closing the gap to flagship models like GPT-5 and actually outperforming many mid-tier closed models (GPT-4o, GPT-5-mini, o4-mini, Gemini-2.5-Flash) on the metrics that matter for production.
%20Average%20cost%20per%20user%20query.png)
.png)
What does this mean for enterprises?
This framework is generalizable to other enterprise AI agents. You can encode your domain constraints and tools into simulation components, and translate “good work” into measurable signals and rewards for RFT. By post-training your agent, you can achieve better performance than agents based on frontier commercial LLMs, at a fraction of the cost and latency, while owning the model as your propreitary IP.
To schedule a platform demonstration, please contact hello@veris.ai or veris.ai/demo.