
Technical Report: How Reinforcement Fine-tuning Trains Enterprise-Grade Domain-specific Agents

Introduction
Enterprises need domain-specific agents that can reliably operate within their own data, tools, and workflows. Agents built with larger enterprise LLMs lack the specificity and run-time performance for most enterprise agentic applications. Post-training is a powerful tool to improve performance and realize benefits in accuracy, cost, and latency.
We post-trained a cybersecurity threat detection AI agent with reinforcement fine-tuning (RFT) using Veris AI’s simulation environment. This AI agent generates high-quality Sigma Rules based on user instruction. The result is a domain-specific AI agent operating on a small local model that performs on par with major commercial LLMs but at a fraction of the cost and latency.
This technical report provides the technical details and experimentation results. You can read a high-level overview in the companion blog.
What are sigma rules?
Sigma rules are standardized detection rules for security logs. They are open, YAML-based detection signatures for log data that gives defenders a vendor-agnostic way to describe and share threat detection logic across different SIEM and log platforms.
Generating sigma rules is a hard problem for an AI agent. Field names must match real log schemas and Windows event IDs, and the YAML must parse correctly. The Sigma schema must always validate, and operators and logic must make sense for the described threat scenario. A rule that looks plausible but uses a fake field or wrong event ID is useless.

Validating a generated rule is also challenging, as there are many ways of describing the same rule and a human expert or LLM-as-a-judge both struggle with validating them.
Supervised fine-tuning (SFT) trains a model on static input–output pairs so it can imitate the structure and style of good Sigma rules — the YAML layout, the fields, and the patterns detection engineers use. SFT never executes those rules or interacts with real logs, it has no sense of whether the rule actually detects the behavior it describes. It learns the form, not the function.
The only way to train that behavior is to generate a rule, run it, score it, and update. That’s learning from experience -> RL
However, RFT is a great way to train this agent. To understand this, let’s look at how a sigma rule can be validated:
- YAML must be valid
- logsource must match real event semantics
- field names must be exact
- detection logic must fire on ground-truth logs
Any mistake shows up instantly through a tool like Chainsaw, an open-source engine that runs Sigma rules directly against Windows event logs. Chainsaw parses EVTX files, applies the rule’s logic, and reports exactly what matched and what didn’t: IoU, false positives, false negatives, and structural correctness. The feedback is immediate and objective, a pure signal. That kind of determinism is what makes Sigma such an effective proxy for any structured enterprise task where correctness with deterministic evaluation.
How does RFT work?
At its core, reinforcement fine-tuning (RFT) is about letting models learn directly from whether their actions actually work, instead of from labels or human preference guesses. It’s especially powerful for tasks that can be defined in a verifiable way, where you can write code or rules that say “this output is correct, this one is not.” That’s the same spirit as Reinforcement Learning with Verifiable Reward (RLVR): if you can formalize success, you can train toward it.
On the Veris platform, the loop looks like this:
- The agent proposes an action or a full solution in the simulation engine.
- The Veris evaluation engine scores it, using rules, constraints, and code-based checks.
- In Veris optimization engine, the policy model adjusts its behavior to earn higher rewards over time.
No synthetic preference labels or painstakingly curated gold sets are needed. Improvements are grounded in how your systems work. Instead of learning from the aggregate internet, the model learns from enterprise internal logic, data schemas, risk thresholds, compliance rules, and operational playbooks.
When you combine that with simulation, the training signal becomes even richer. The model doesn’t just learn from static before/after examples; it learns from dynamic, state-dependent scenarios that mirror how enterprise systems behave under real conditions including broken APIs, partial data, ambiguous user input, and so on. Over many iterations, this is how Veris turns smaller open-source models into reliable operators for high-precision enterprise workflows.
Baselines: Closed Models vs Reality
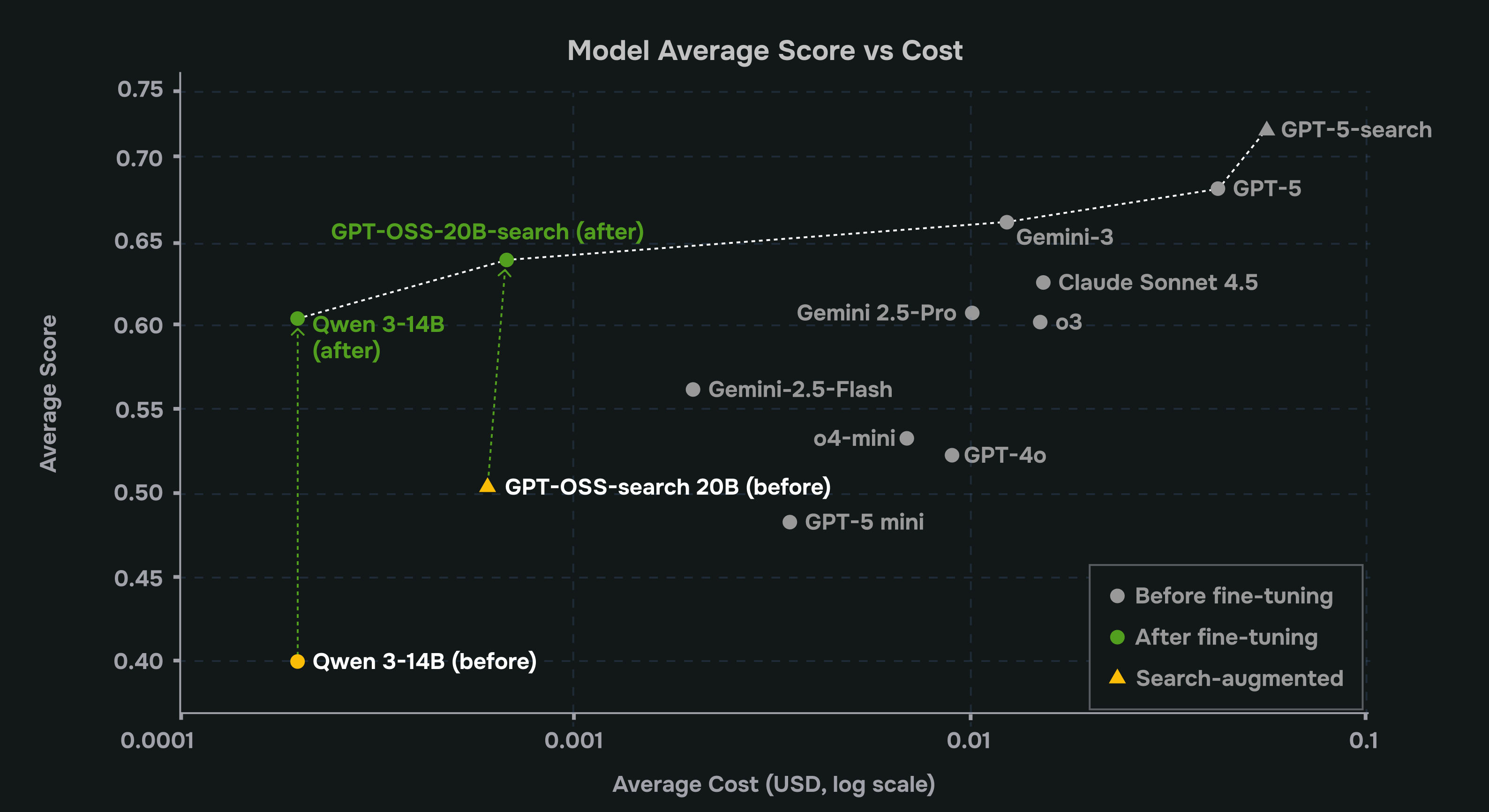
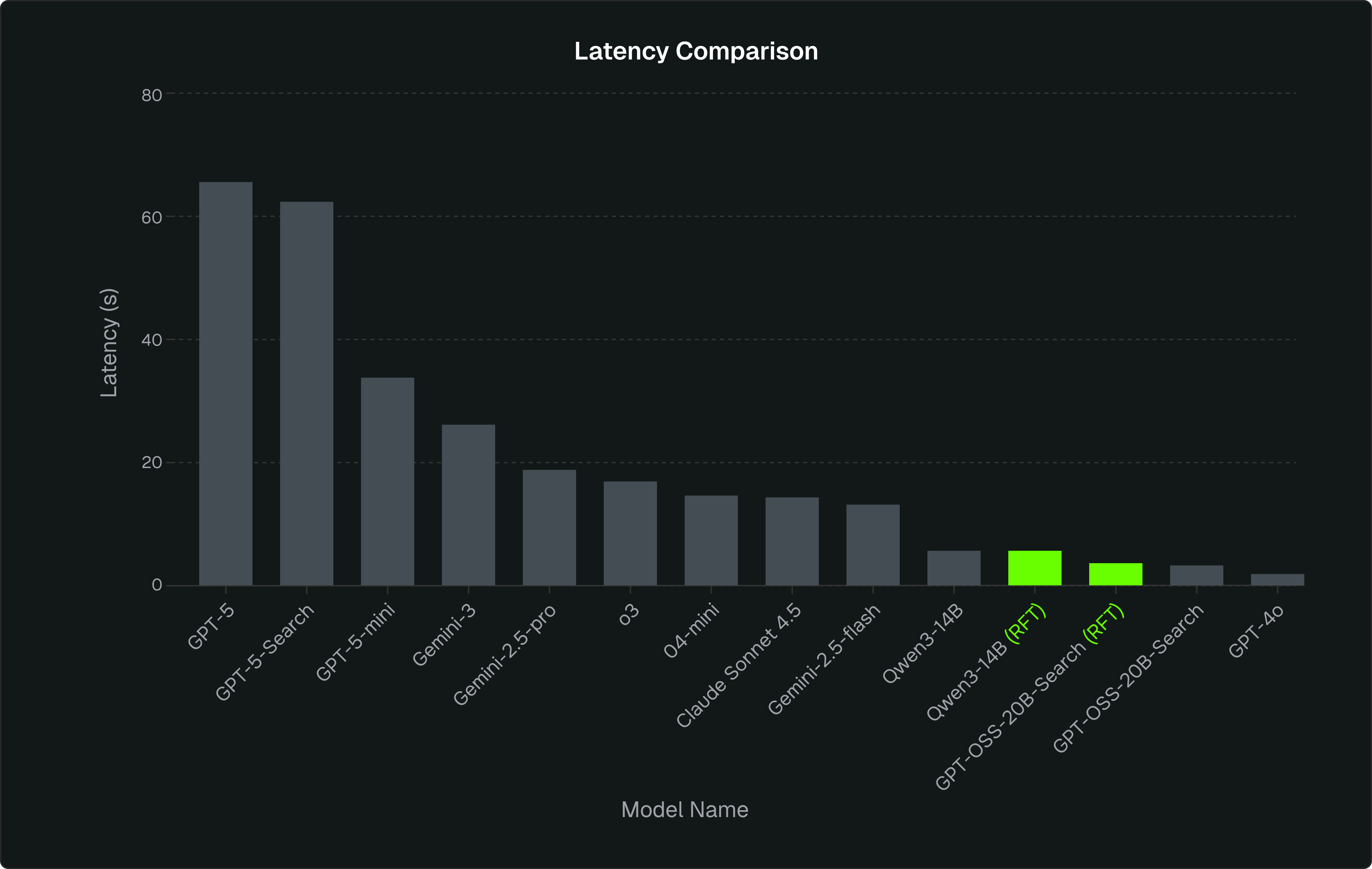
We created a benchmark with closed models. In our experiments, GPT-5 was the clear gold standard. It was the most accurate and the most consistent, but also by far the slowest and most expensive option. For most production pipelines, there is a trade-off of paying a premium price for every call, accepting much higher latency, and using an external provider.
Every other model (GPT-4o, GPT-5-mini, o4-mini, Gemini-2.5-flash) outputted incorrect event IDs, invalid metadata, missing conditions, rules that didn’t actually fire on real logs, and outputs that changed with tiny prompt variations. They were usable for surface-level output like summaries, explanations, simple heuristics, but not trustworthy enough to be the backbone of production-grade detection.
This is the uncomfortable gap most teams feel: models that are cheap and fast but unreliable, versus models that are accurate but slow and expensive. That gap is exactly where RFT becomes powerful, because instead of choosing between “too weak” and “too costly,” companies can take a smaller, faster model and train it to behave like the strong one on the specific workflows that matter to them.
We also trained and evaluated variants with access to a simple web search tool. Search lets the agent look up missing event IDs, field names, and product details instead of guessing, mirroring how a security analyst would pull documentation before writing a rule. By comparing small and large models with and without search, we can see how much retrieval alone closes the gap versus relying on a much larger model’s latent knowledge.
The RFT training loop
We plugged Qwen3-14B and GPT-OSS-20B into our SigmaForge environment and wrapped them in a deterministic GRPO loop. Each generated Sigma rule was evaluated against ground-truth logs using Chainsaw, so the reward signal came directly from whether the rule actually fired correctly in practice. The models only produced the parts of the rule that affect behavior, logsource and detection, so every update was tied to real correctness and validity, not cosmetic formatting.
For data, we started with ~100 Sigma rules from SigmaHQ and sample detection logs from two public repositories evtx-samples and hayabusa‑evtx. On top of this, we built a simulation where user personas issue the kinds of detection requests security analysts actually make. The agent responds with a Sigma rule; Chainsaw immediately runs it against real logs. The model trains inside that loop: personas → queries → rule generation → real-world validation.
For GPT-OSS-20B, we also introduced web search as a tool to test the impact of retrieval in the same pipeline. When the agent lacked information (event IDs, tool names, ATT&CK techniques) it could choose to issue a search query or go straight to rule generation. After RFT, the agent’s search frequency increased by 16%, indicating it learned to proactively pull missing context rather than hallucinate. In this experiment, we constrained it to a single search turn per request.
Every generated rule was evaluated end-to-end: YAML validity, correct logsource semantics, and an IoU score computed by running the rule against real logs and comparing detections to ground truth. That closed loop—generation, execution, scoring—is the core of how RFT turns “pretty good” open models into highly reliable Sigma rule authors.
The reward was a weighted combination of those signals:
reward = 0.1 * yaml_valid
+ 0.3 * logsource_correct
+ 0.7 * iou_score
Training Operations
We ran the experiments on 8×A100-80GB GPUs. Qwen3-14B was trained with full fine-tuning for 150 steps, completing in approximately six hours. GPT-OSS-20B was trained with LoRA and single-turn retrieval for 120 steps, which took twelve hours due to the added multi-turn interaction per iteration. Each step used a batch size of 8 with 8 rollouts. Chainsaw required around 12 seconds per generated rule to execute the Sigma logic against the EVTX logs and compute IoU, false positives, false negatives, and structural correctness.
Results, Metrics, and Comparisons to Frontier Models
| Model | Average Score | Valid Sigma Rule % | Correct logsource % | IOU score | Latency (s) | Avg Cost (Input + Thinking + Output) |
|---|---|---|---|---|---|---|
| GPT-5 | 0.6815 | 95.7 | 81.4 | 0.419 | 65.8 | 0.042 |
| GPT-5-mini | 0.4819 | 97.1 | 72.9 | 0.239 | 34.17 | 0.0035 |
| o3 | 0.601 | 100 | 82 | 0.324 | 17.10 | 0.015 |
| o4-mini | 0.5324 | 100 | 80 | 0.272 | 15.03 | 0.007 |
| GPT-4o | 0.5220 | 100 | 75.7 | 0.27 | 2.09 | 0.009 |
| Gemini-3 | 0.6600 | 100 | 83 | 0.4 | 26.49 | 0.0125 |
| Gemini-2.5-pro | 0.6073 | 100 | 81.4 | 0.342 | 19.14 | 0.01 |
| Gemini-2.5-flash | 0.5612 | 100 | 82.9 | 0.298 | 13.48 | 0.002 |
| Claude Sonnet 4.5 | 0.6244 | 100 | 81.4 | 0.407 | 14.64 | 0.015 |
Table 1. Baseline / Closed Source Inference
| Model | Average Score | Valid Sigma Rule % | Correct logsource % | IOU score | Latency (in seconds) | Average Num Search in the set | Average Cost for this Task |
|---|---|---|---|---|---|---|---|
| Qwen3-14B (before) |
0.401 | 92.9 | 67.1 | 0.1737 | 5.82 | - | 0.0002 |
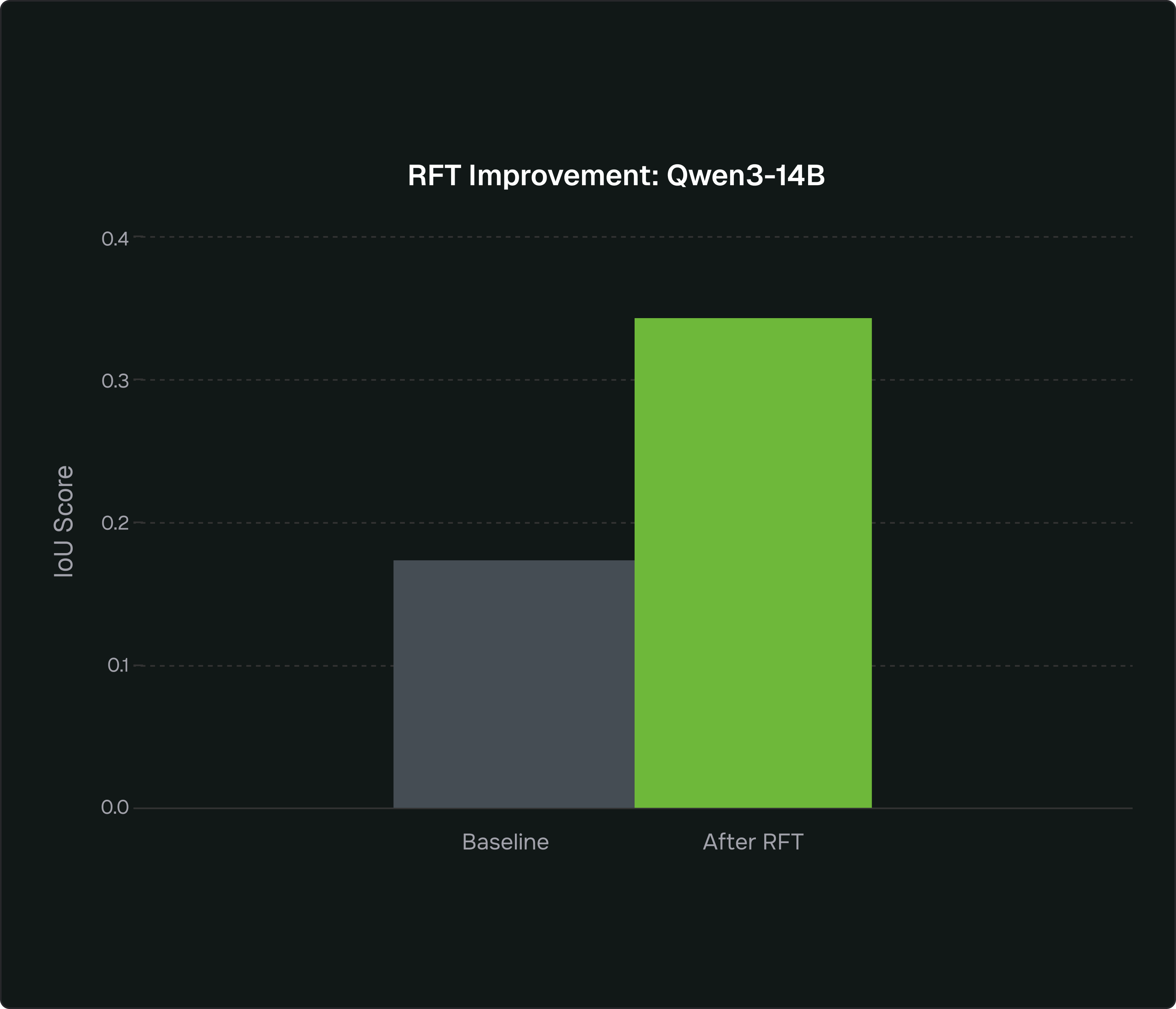
| Qwen3-14B (after) |
0.604 | 100 | 77 | 0.3436 | 5.82 | - | 0.0002 |
| With Search | |||||||
| GPT-5-search | 0.717 | 100 | 90% | 0.437 | 63 | 1 | 0.056 |
| GPT OSS 20B (before) |
0.5051 | 100 | 74% | 0.23 | 3.6 | 0.6 | 0.0006 |
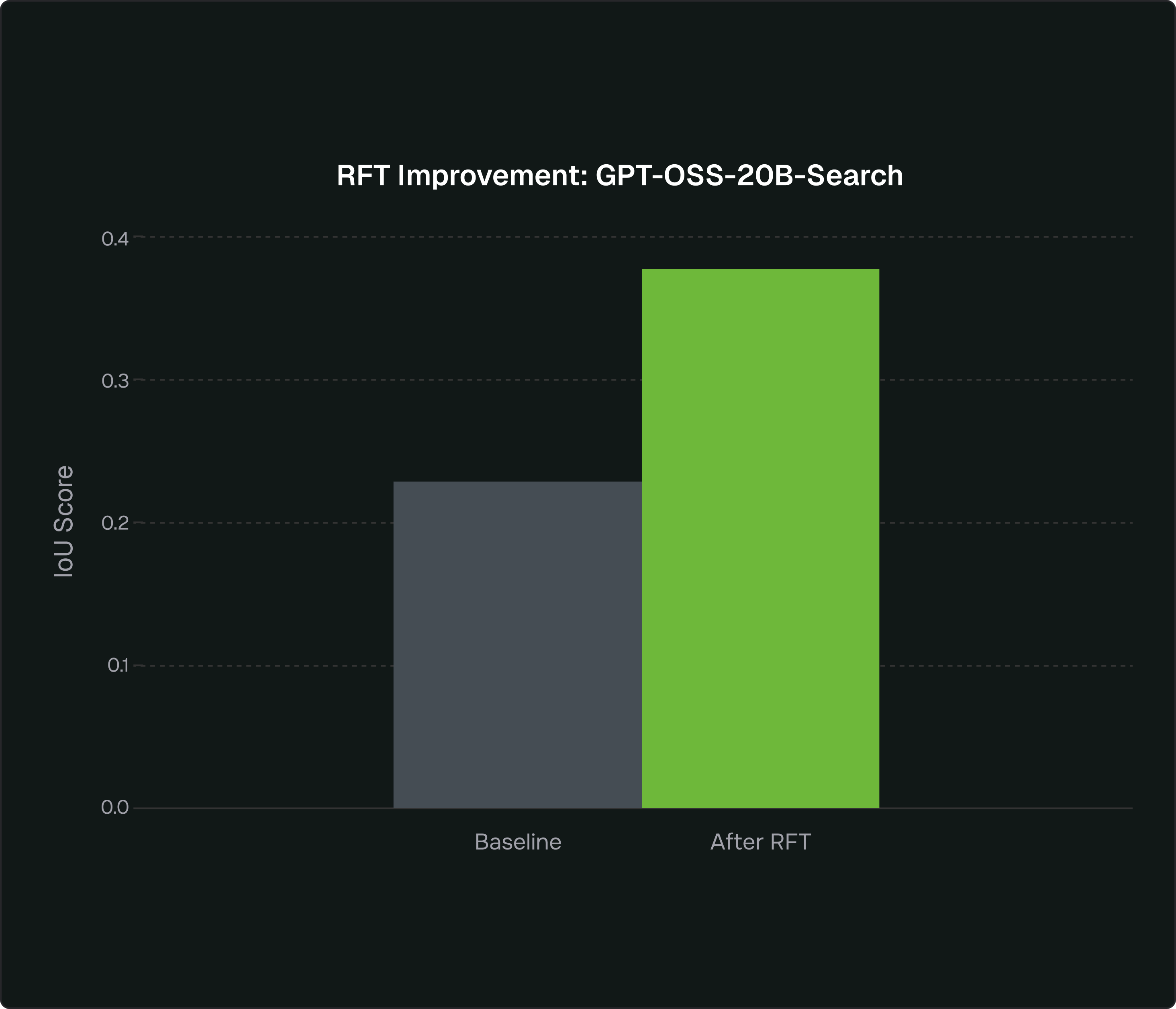
| GPT OSS 20B (after) |
0.6371 | 100 | 75% | 0.377 | 3.8 | 0.72 | 0.00067 |
Table 2: Trained Models (with Comparison)
%20Average%20cost%20per%20user%20query.png)
.png)
Rule: VSSAudit – Before/After
Scenario: VSSAudit
User query: Could you create a rule to monitor for the registration of VSSAudit, potentially indicating shadow copy activity related to credential dumping?
Before
logsource:
product: windows
category: registry_set
detection:
selection:
TargetObject|contains: \Services\VSSAuditAfter – added condition field, event ids, appropriate selection source, fixed logsource
logsource:
product: windows
service: security
detection:
selection:
AuditSourceName: VSSAudit
EventID:
- 4904
- 4905
condition: selectionRule: Binaries – Before/After
Scenario: Binaries
User query: Hey, can we set up something to catch when attackers rename and run different binaries in our Windows environment? I heard using Sysmon's OriginalFileName might help.
Before
logsource:
product: windows
category: process_creation
detection:
selection:
OriginalFileName|contains: .exe
filter_main:
Image|startswith:
- C:\Windows\System32\
- C:\Windows\SysWOW64\
condition: selection and not filter_mainAfter
logsource:
product: windows
category: process_creation
detection:
selection:
OriginalFileName:
- Cmd.Exe
- CONHOST.EXE
- 7z.exe
- 7za.exe
- WinRAR.exe
- wevtutil.exe
- net.exe
- net1.exe
- netsh.exe
- InstallUtil.exe
filter:
Image|endswith:
- \cmd.exe
- \conhost.exe
- \7z.exe
- \7za.exe
- \WinRAR.exe
- \wevtutil.exe
- \net.exe
- \net1.exe
- \netsh.exe
- \InstallUtil.exe
condition: selection and not filterRule: MITRE – Before/After
Scenario: MITRE
User query: Establish a detection for anomalous child process activity under Office suite applications, particularly for MITRE ATT&CK techniques T1218.010 and T1047.
Before
logsource:
product: windows
category: process_creation
detection:
selection:
ParentImage|endswith:
- \WINWORD.EXE
- \EXCEL.EXE
- \POWERPNT.EXE
- \PUB.EXE
Image|endswith:
- .exe
- .bat
- .ps1
- .vbs
- .cmd
CommandLine|contains:
- powershell
- cmd
- regsvr32
- msiexec
- taskkill
- wmic
filter:
Image|startswith: C:\Program Files\Microsoft Office\
condition: selection and not filterAfter – added a better filter criteria
logsource:
product: windows
category: process_creation
detection:
selection:
ParentImage|endswith:
- \mspub.exe
- \excel.exe
- \winword.exe
- \powerpnt.exe
- \outlook.exe
Image|endswith:
- .exe
- .bat
- .ps1
- .vbs
- .js
- .cmd
filter:
Image|endswith:
- \taskhost.exe
- \explorer.exe
- \cmd.exe
- \powershell.exe
condition: selection and not filter
The Takeaway
Once an agent is connected to your decision workflow, simulation becomes the engine of the verification loop. It exposes the agent to how your systems actually behave: state changes, adversarial paths, long workflows, timing quirks, and the edge cases no dataset will ever capture. RFT turns that stream of behavior into a signal. The environment becomes the curriculum, and the agent aligns to your internal rules and semantics instead of the world at large.
The Sigma workflow captured a complete enterprise detection process: real logs, real validation logic, and real constraints. That same structure exists across countless enterprise tasks. Any workflow with deterministic checks or programmatic validation can plug into the same loop. When simulation and decision logic drive training together, agents learn the behavior of your environment and continue to adapt as it evolves—without relying on oversized closed-source models.
At Veris, we turn enterprise systems into the training environment itself. By running your decision logic, logs, and policies through our simulation and RFT pipeline, small or custom models become tightly aligned operators that Veris trains and serves as agents inside your infrastructure.
To schedule a platform demonstration, please contact hello@veris.ai or veris.ai/demo.