
RFT Can Make Agents with Small Models Outperform Big Models on Enterprise Tasks

Savi Security is building the world's best scam detection engine. Veris AI is pioneering simulation sandbox environments for training and evaluating AI agents. This blog documents a joint research initiative exploring how dynamic evaluation methodologies and reinforcement fine-tuning can advance the state of the art in adversarial AI domains like scam detection.
Executive Summary
As AI-powered scams grow more sophisticated, the tools built to detect them must evolve just as quickly. Savi Security and Veris AI partnered on a research initiative to explore a critical question at the intersection of AI safety and agent evaluation: Can dynamic simulation environments and novel fine-tuning methodologies produce meaningfully better scam detection capabilities than static benchmarks alone?
This blog presents the findings of that collaboration. It proposes a comprehensive evaluation architecture, "ScamSim", designed to stress-test scam detection agents against the full complexity of real-world adversarial conditions. It then documents an experiment conducted jointly by both teams, applying Veris's simulation platform and reinforcement fine-tuning techniques to Savi's scam taxonomy and detection framework. The results illuminate promising directions for the broader AI agent community, particularly for anyone building AI systems in adversarial, high-stakes domains where static evaluation falls short, or companies looking to switch from large expensive commercial models to cost-effective local small models.
While Savi continues to evolve its production approach to scam detection and currently leveraging frontier foundation models for maximum accuracy, this research represents an important waypoint in understanding the design space for next-generation scam detection systems. The methodologies explored here inform Savi's long-term technical roadmap and demonstrate Veris's capabilities in agent simulation, training, and reinforcement fine-tuning.
Enterprises do not need a model that can write poetry. They need agents that can make correct, repeatable decisions inside real workflows, whether inbox triage, fraud flags, support routing, SMS filtering, call-center follow-ups, or a myriad of other applications. These are high-volume tasks where latency and cost compound, and where a “pretty good” model still creates a lot of operational pain.
The usual assumption is that you need a bigger LLM to get reliable results. This post argues the opposite: for many enterprise tasks, small local models (SLMs) are enough, and with reinforcement fine-tuning (RFT), they can outperform much larger models.
We’ll use a simple, broadly applicable case study: scam detection across emails, texts, and phone call transcripts, with the agent allowed to use a search tool when it lacks information. Starting from ~80% accuracy on a small model (Qwen3-4B), RFT pushes it to 94.4%, beating strong commercial baselines while running much faster and cheaper.
Reliability at Scale
Enterprises do not struggle because models cannot understand text. They struggle because production workflows demand performance that holds up at scale. In our use case, a scam detector has to be consistent across thousands of messages, fast enough for real-time routing, and cheap enough to run everywhere without inference becoming a runaway cost center.
It also needs to be tool-grounded. Some decisions require verification, like checking a sender domain or a vendor claim, and the model should know when to look things up and when not to. Most importantly, performance has to be measurable so you can regression-test it, iterate, and improve over time.
Big commercial LLMs can look strong in demos, but they often fail in the most expensive way: “pretty good” becomes unpredictable at scale, and the default fix is more calls to a bigger model. The real question is whether you can take a small model and train it to behave like a specialized enterprise agent under these constraints. That’s exactly what RFT is good at.
The task: scam detection across email, SMS, and phone call transcripts
We trained and evaluated an agent that reads one of three inputs: email text, SMS/text messages, or phone call transcripts. For each message, it predicts whether the content is a scam and, by extension, how it should be handled in a workflow, such as flagging, escalating, or ignoring.
The agent also had access to a search tool. That matters in practice because many decisions require lightweight verification, like checking a sender domain, validating a vendor name, or sanity-checking a claim in the message.
In the previous post, we showed how RFT can turn a small model into a specialist for a tightly constrained domain task like Sigma rule generation. Here, we look at the other end of the spectrum: a workflow that is widely applicable, where the hard part is not domain expertise, it’s operating reliably under production constraints like tool use, cost, and latency at scale.
Experiment Results
We used the Veris AI simulation sandbox environment to both create training data for training and for evaluating performance before and after RFT. Veris’s environment contains simulated users and tools that act based on a generated set of test scenarios that cover a large range of realistic situations that might happen in production.
We used approximately 2,000 simulation runs in the Veris AI sandbox to generate training scenarios and supervision data, with each run allowing up to 3 search turns. We then applied GRPO-based post-training to a Qwen3 4B model, training on a single node with 4× A100 40GB GPUs.
Post RFT, the small Qwen3 model became the best performer on Veris benchmark. It hits 94.4% accuracy with 5.42s average latency and ~1 search per sample. The baseline version of the same model was around ~80%, so this is a +15.2 point gain from post-training. This performance is also substantially faster than the large-model baselines while exceeding their accuracy. Latency per sample is roughly 2× to 13× faster than the other models in our study. The three figures below show the comparison across the three dimensions of accuracy, latency, and accuracy.
.png)
.png)
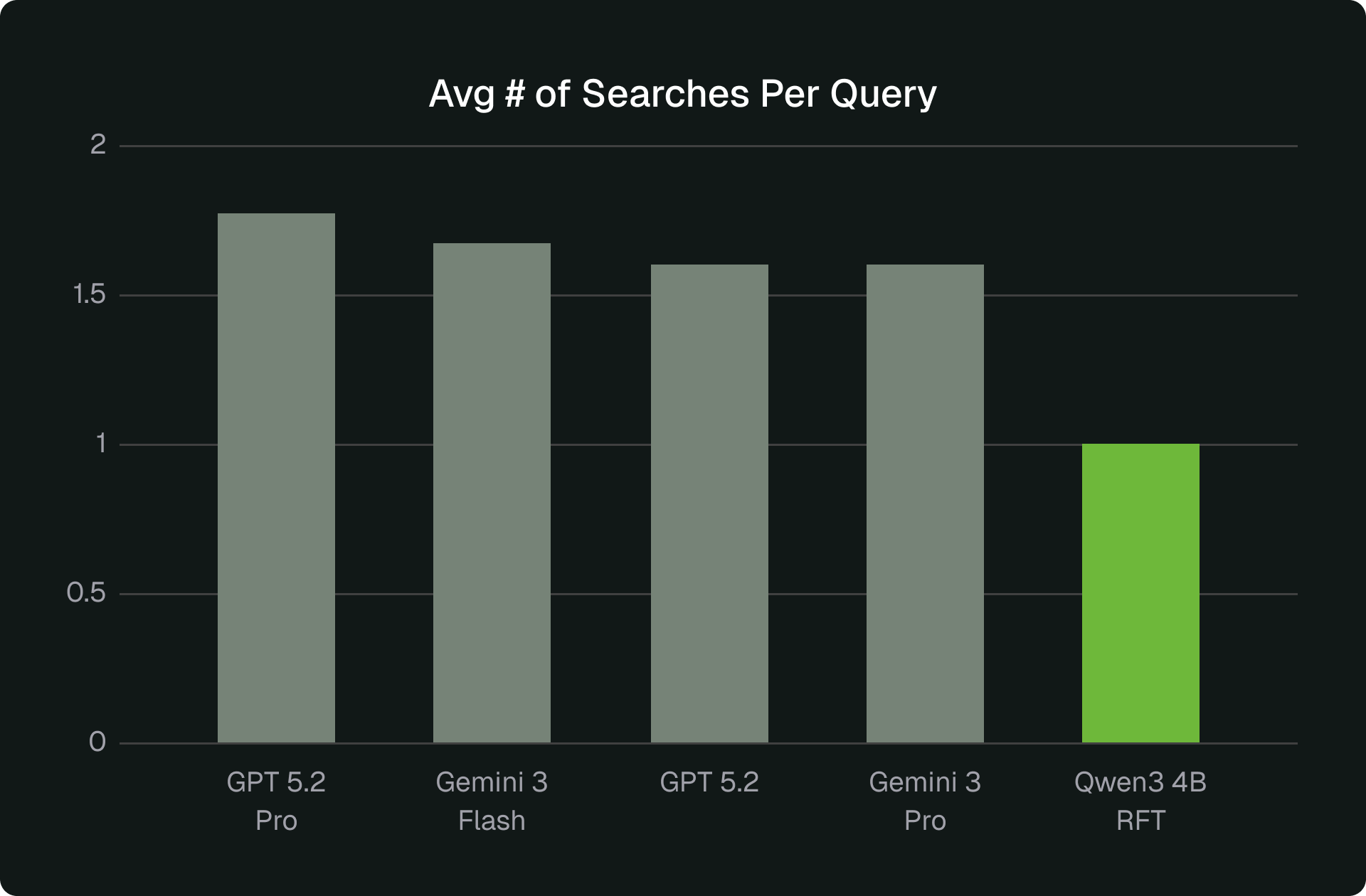
The result is not just a higher score, it’s a better operating point. Post RFT, the model is both more accurate and faster, with stable tool behavior. That makes capacity planning simple: latency is predictable and search volume is controlled.
These results validated the core research hypothesis: RFT can produce a small, specialized model that competes with frontier models on a well-defined adversarial task. For Savi, this experiment also provided valuable signals on how their scam taxonomy performs as a training substrate, insights that inform their ongoing work on detection accuracy regardless of which model architecture powers the production system.
Why RFT works here
There are many ways to improve the performance of an AI agent, including prompting, adding tools, changing the architecture, or different flavors of fine-tuning. Adding tools and changes in architecture can add new capabilities and dimensions to the agent and prompting can add missing context and knowledge. However none of them alone can reliably change agent behavior. Scam detection failures are usually not about missing knowledge, they’re about decision policy: what signals to trust, what to ignore, and when to verify or search. RFT trains that policy directly by rewarding outcomes under the same constraints the agent will face in production and it is the only robust way of embedding new behavior in the agent.
Instead of collecting huge labeled datasets, we built a simulated workflow with Veris AI. Personas generate realistic messages from ground-truth data across email, text, and call transcripts, including adversarial and borderline cases. The agent responds, can use search when needed, and gets scored on whether the final decision was correct. Over time, the model learns stronger scam cues and when tool use actually adds value.
The key point is that the environment enforces what “good” looks like. It doesn’t care whether an explanation sounds plausible. It cares whether the decision is correct and whether the agent stays efficient inside the workflow.
Why Veris: you don’t need 100k labels, you need an environment
RL operation has many challenges, mostly around scaffolding and supporting tasks such as creating realistic scenarios (including adversarial edge cases), defining what “success” means in the workflow, and turning that into scoring the model can learn from. Concretely, for an RFT loop, we require to
- generate representative inputs and hard edge cases
- build grading logic that matches real operational outcomes
- track tool traces and reward signals end to end
- run regression eval so improvements don’t break behavior you already rely on
This complex loop requires a shift from training datasets to training environments. Training examples, like the ones used in traditional machine learning, mostly teach imitation. While environments can teach behavior. Because they evaluate the agent the way production does. Veris makes this loop practical by simulating tasks at scale, measuring outcomes, running RFT continuously, and shipping a specialized agent you can actually operate.
What this means for enterprises
If your workflows look like classify, extract, route, verify with tools, or enforce policy, SLMs plus RFT are often the better default. These tasks have clear success criteria, and they run at volumes where cost and latency are no longer secondary metrics, they’re product constraints. Once reliability is trained in, you can deploy broadly without building your system around the runtime and spend-profile of a large model.
Larger general models still make sense when the work is open-ended, when quality is subjective, or when you can’t score outcomes in a stable way. If you don’t have a strong feedback signal, RFT has little to optimize, and general-purpose reasoning and writing become the differentiator again. What matters most is operational reliability: correct decisions, bounded variance, and predictable runtime.
Veris AI makes this repeatable. Simulate the workflow, score outcomes, run RFT, and ship a small model you can actually operate. To schedule a platform demonstration, please contact hello@veris.ai or visit veris.ai/demo.